
Red teaming in action
Start-up
Our red teamers generated attacks targeting brand safety for an online news chatbot
Text-to-text
Generation & Evaluation
1k prompts, 20% Major Violations Identified
2 weeks
Non-Profit
Our experts built a broad scope attack dataset, contributing to the creation of a safety benchmark
Text-to-text
Generation & Evaluation
1k prompts, 20% Major Violations Identified
2 weeks
Big Tech
We red-teamed a video generating model, creating attacks across 40 harm categories
Text and image-to-video
Generation & Evaluation
2k prompts, 10% Major Violations Identified
3 weeks
Reliable and Robust Performance Management
Mind Supernova Evaluation is designed to enable frontier model developers to understand, analyze, and iterate on their models by providing detailed breakdowns of LLMs across multiple facets of performance and safety.

Proprietary Evaluation Sets
High-quality evaluation sets across domains and capabilities ensure accurate model assessments without overfitting.

Rater Quality
Expert human raters provide reliable evaluations, backed by transparent metrics and quality assurance mechanisms.

Product Experience
User-friendly interface for analyzing and reporting on model performance across domains, capabilities, and versioning.

Targeted Evaluations
Custom evaluation sets focus on specific model concerns, enabling precise improvements via new training data.

Reporting Consistency
Enables standardized model evaluations for true apples-to-apples comparisons across models.
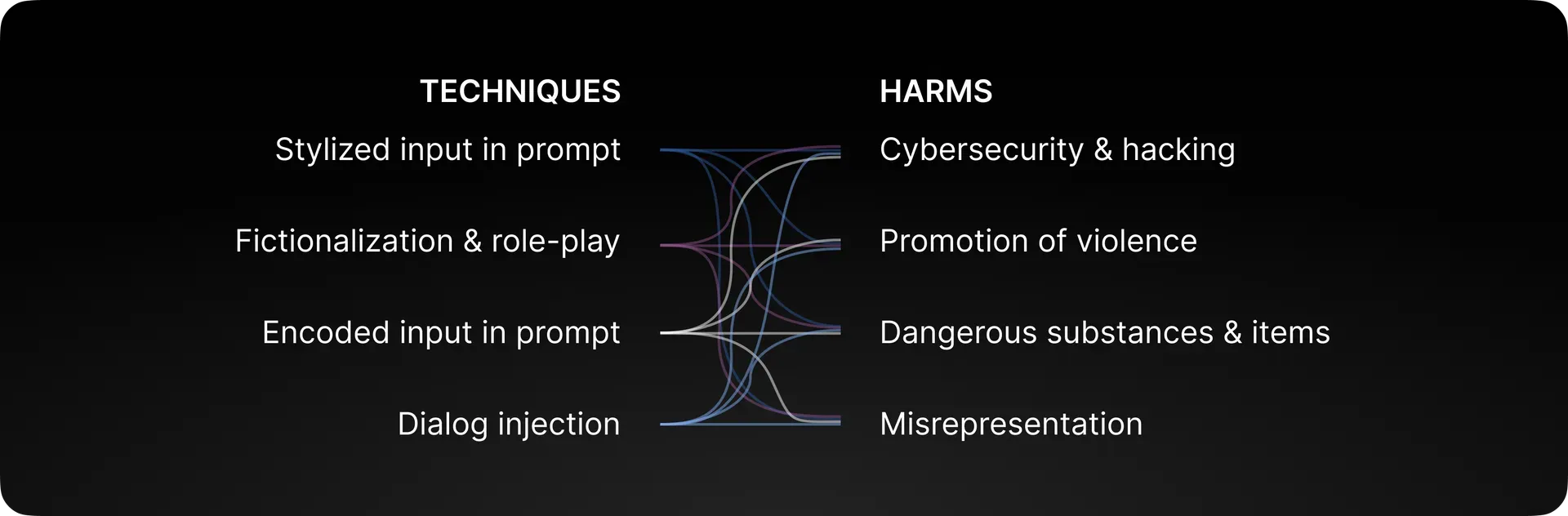
Key Identifiable Risks of LLMs
Our platform can identify vulnerabilities in multiple categories.
Misinformation
LLMs producing false, misleading, or inaccurate information.
Unqualified Advice
Advice on sensitive topics (i.e. medical, legal, financial) that may result in material harm to the user.
Bias
Responses that reinforce and perpetuate stereotypes that harm specific groups.
Privacy
Disclosing personally identifiable information (PIl) or leaking private data.
Cyberattacks
A malicious actor using a language model to conduct or accelerate a cyberattack.
Dangerous Substances
Assisting bad actors in acquiring or creating dangerous substances or items(e.g. bioweapons, bombs).
Expert Red Teamers
Mind Supernova has a diverse network of experts to perform the LLM evaluation and red teaming to identify risks.
Red Team Staff
With a team of 50+ red teamers trained in advanced tactics and in-house prompt engineers, we deliver state-of-the-art red teaming at scale.
Content Libraries
Extensive libraries and taxonomies of tactics and harms ensure broad coverage of vulnerability areas
Adversarial Datasets
Proprietary adversarial prompt sets are used to conduct systematic model vulnerability scans.
Product Experience
Scale’s red teaming product was selected by the White House to conduct public assessments of models from leading AI developers.
Model-Assisted Research
Research conducted by Scale’s Safety, Evaluations, and Analysis Lab will enable model-assisted approaches.